ClickHouse简介
OLAP场景的特征
- 大多数是读请求,写是批量写入(每次>=1000行),很少更新和删除数据
- 查询时需要扫描很多行数据,但结果只包含某几列
- 事务不是必须的,对数据一致性要求低
- 查询结果明显小于源数据
列式存储更适合OLAP场景
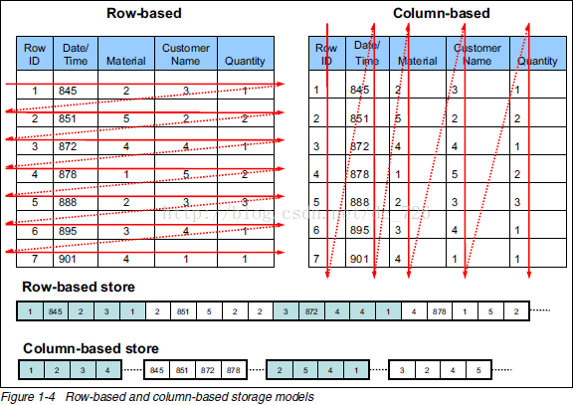
对于分析类查询,通常只需要某几列,而行式数据库会把所有列读取出来。列式数据库允许你只读取需要的那几列,降低了I/O。
数据是按列存储的,读取的时候也总是批量读取,所以很适合做压缩,进一步降低I/O。


ClickHouse介绍
ClickHouse来自来自战斗名族俄罗斯,是一款用于大数据实时分析的列式数据库管理系统。通过向量化执行以及对cpu底层指令集(SIMD)的使用,它可以对海量数据进行并行处理,从而加快数据的处理速度。主要优点有:
-
压缩率高。平均压缩比基本上是5倍左右,假设有20亿行数据,每行占用200字节,那么压缩前是400GB,压缩后是80GB;
-
读取速度飞快。如果一个磁盘允许以400MB/s的速度读取数据,并且数据压缩率是3,则数据的处理速度为1.2GB/s。这意味着,如果你是在提取一个10字节的列,那么它的处理速度大约是1-2亿行/s;
-
写入速度快,50-200M/s,对于批量写入非常适用;
-
对内存的依赖性不大。许多的列式数据库(如 SAP HANA, Google PowerDrill)只能在内存中工作,这种方式会造成比实际更多的设备预算。ClickHouse被设计用于工作在传统磁盘上的系统,它提供每GB更低的存储成本,但如果有可以使用SSD和内存,它也会合理的利用这些资源;
-
CPU利用率高:多核心并行处理、向量引擎;
-
丰富的统计函数;
-
部署简单,支持集群、异步复制。
ClickHouse并非万能的,正因为ClickHouse处理速度快,所以也是需要为“快”付出代价。选择ClickHouse需要有下面注意以下几点:
- 不支持事务,不支持UPDATE、DELETE;
- 不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下;
- sql满足日常使用80%以上的语法,join写法比较特殊;最新版已支持类似sql的join,但性能不好;
- 尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作,因为ClickHouse底层会不断的做异步的数据合并,会影响查询性能,这个在做实时数据写入的时候要尽量避开;
- Clickhouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的cpu去执行,所以ClickHouse不能支持高并发的使用场景,默认单查询使用cpu核数为服务器核数的一半,安装时会自动识别服务器核数,可以通过配置文件修改该参数;
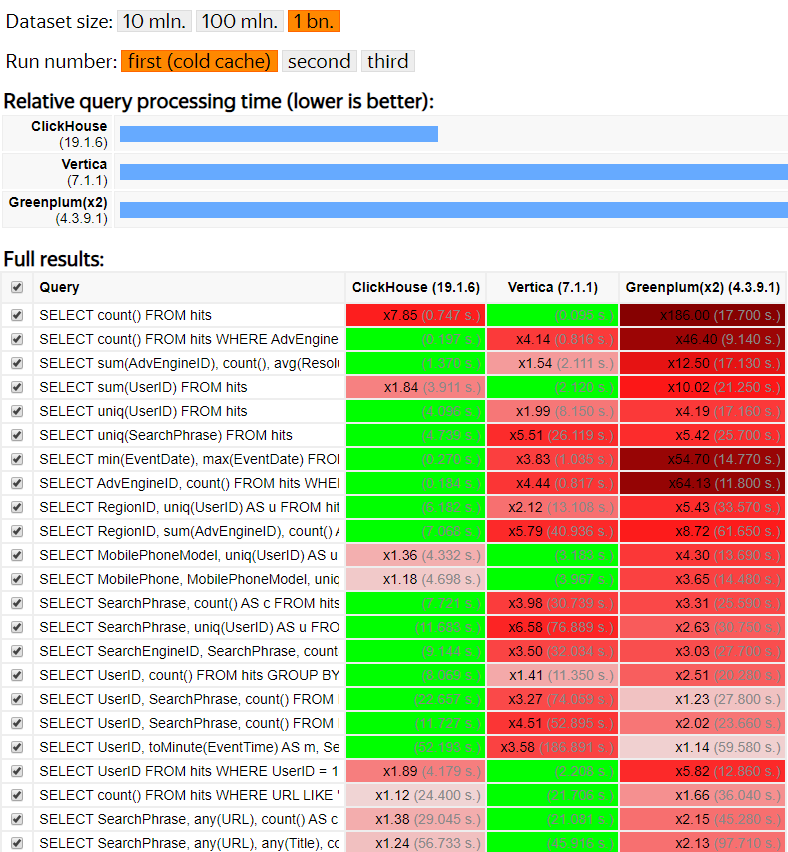
ClickHouse的性能测试表现:
压缩算法
ClickHouse支持两种压缩算法:LZ4和ZSTD,默认采用的算法是LZ4。
LZ4在速度上会更快,但是压缩率较低,ZSTD正好相反。尽管ZSTD比LZ4慢,但是相比传统的压缩方式Zlib,无论是在压缩效率还是速度上,都可以作为Zlib的替代品。
压缩原理:
压缩前:abcde_bcdefgh_abcdef
压缩后:abcde_(5,4)fgh_(14,5)f
括号里面的两个数字可以锁定重复项,比如第一个括号的5是代表向前移动5个字节,4表示长度,那么解压的时候就可以得到“bcde”字符串,重复项越多,压缩效果越明显。
要修改压缩算法需要修改配置文件:
<compression incl="clickhouse_compression">
<case>
<method>zstd</method>
</case>
</compression>
配置文件
- config.xml:端口配置、本地机器名配置、内存设置等
- metrika.xml:集群配置、ZK配置、分片配置等
- users.xml:权限、配额设置
表引擎
MergeTree
这是最常用的引擎,当我们向表里批量插入数据时,数据按主键排序并保存到一个新的分块中,然后在后台会有线程去做异步的合并,这就是 MergeTree 的名称来源,主要有以下特点:
- 基于分区键(partitioning key)的数据分区分块存储
- 数据索引排序(基于primary key和order by)
- 支持数据复制(带Replicated前缀的表引擎)
索引结构
主键索引是稀疏的,稀疏索引占用空间小,可以把索引文件整个捞到内存,加快查询速度。
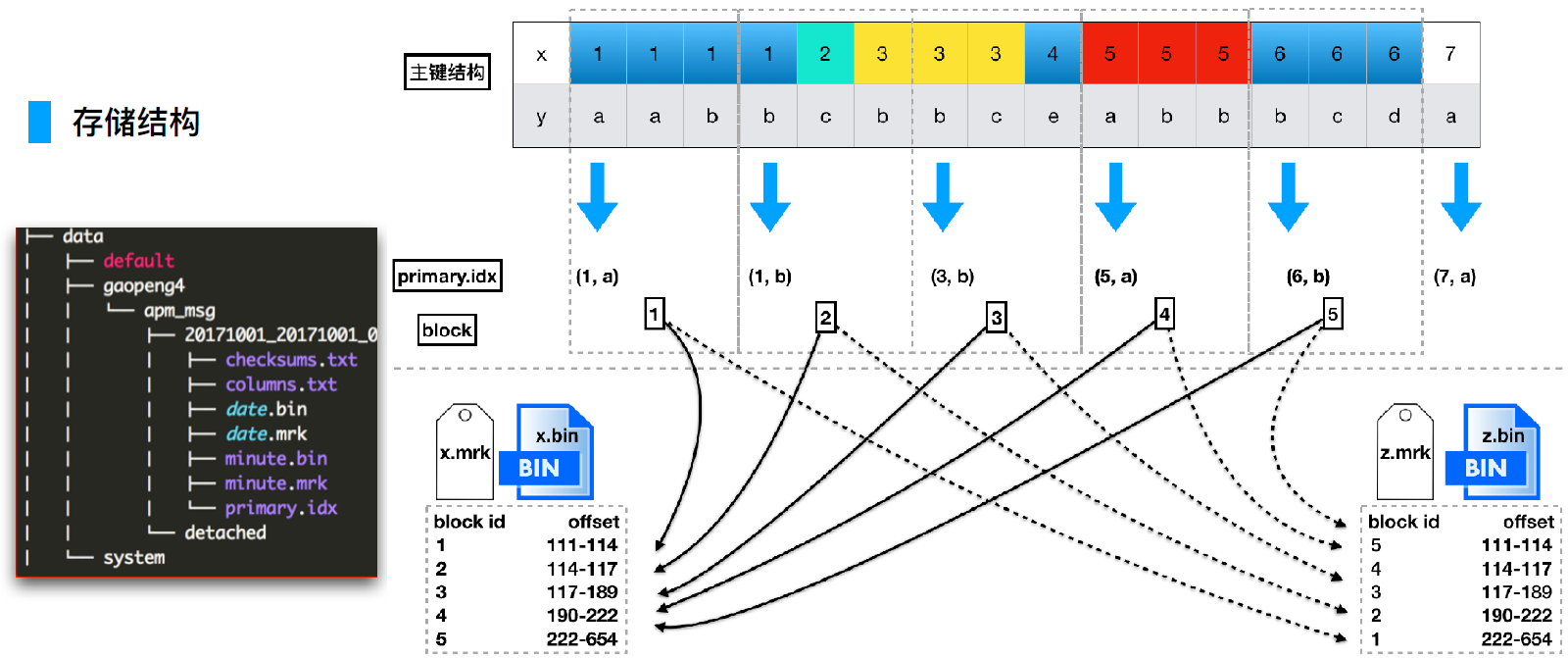
查找过程:
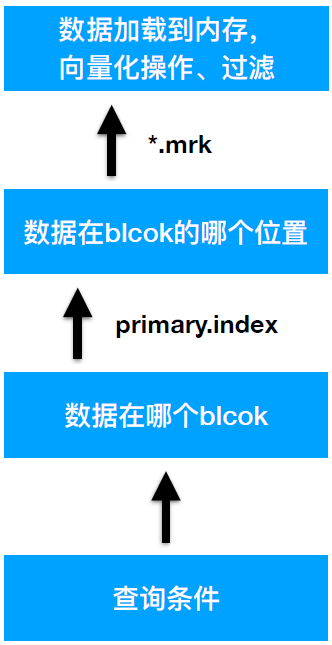
跟MySQL的B+树索引遵循最左原则不同,ClickHouse里面查询非最左索引的列还是可以用到索引的,只是过滤的效果没有那么好。
创建表示例:
CREATE TABLE visits
(
VisitDate Date,
Hour UInt8,
ClientID UUID
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(VisitDate) # 分区
ORDER BY Hour; # 排序键,默认情况下主键跟排序键相同。
需要注意的是我们连接ClickHouse的时候需要制定多行模式,不然上面这种多行的SQL会报错:
clickhouse-client --multiline
把MySQL的表导入到ClickHouse:
CREATE TABLE article ENGINE = MergeTree ORDER BY id AS
SELECT * FROM mysql('host:port', 'db', 'article', 'user', 'password');
查看分区信息:
select table,partition,name,active from system.parts where table='ontime';
ReplicatedMergeTree
这个引擎可以结合ZooKeeper实现副本的一致性。需在配置文件中设置 ZooKeeper 集群的地址:
<zookeeper>
<node index="1">
<host>example1</host>
<port>2181</port>
</node>
<node index="2">
<host>example2</host>
<port>2181</port>
</node>
<node index="3">
<host>example3</host>
<port>2181</port>
</node>
</zookeeper>
创建表:
CREATE TABLE tbl
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree(zk路径, 副本名称)
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID));
Distributed
本身不存储数据, 只是做查询转发再聚合返回。可以利用它来做最简单的分布式方案。
Distributed(集群名称, 数据库, 表名, 分片键)
SummingMergeTree
在MergeTree基础上,合并时会把主键相同的行合并,并对数值类型的列进行求和。应用场景:MergeTree存明细数据,SummingMergeTree存汇总数据。
External data
外部表引擎,例如直接对CSV文件进行查询,免去了导入的过程:
clickhouse-client --query="SELECT a, sid FROM tbl" --external --file=/tmp/2.csv --format=CSV --name=tbl --structure='a String, b String, sid UInt8'
| a | sid |
|---|---|
| a1 | 5 |
| a2 | 9 |
| a3 | 2 |
搭建集群
接下来,我们来搭建一个集群,方案是2个分片、每个分片有2个副本。查询的时候直接在分布式表上操作。 修改config.xml,加载集群配置文件,在</yandex>标签上一行加入:
<include_from>/etc/clickhouse-server/metrika.xml</include_from>
host配置取消::那一行的注释,不然连分布式表的时候会报错connection refused:
<!-- Listen specified host. use :: (wildcard IPv6 address), if you want to accept connections both with IPv4 and IPv6 from everywhere. -->
<listen_host>::</listen_host>
新建metrika.xml,填写集群配置:
<yandex>
<clickhouse_remote_servers>
<test_cluster>
<shard>
<!-- Optional. Shard weight when writing data. Default: 1. -->
<weight>1</weight>
<!-- Optional. Whether to write data to just one of the replicas. Default: false (write data to all replicas). -->
<internal_replication>false</internal_replication>
<replica>
<host>10.250.160.187</host>
<port>9000</port>
</replica>
<replica>
<host>10.250.160.188</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>10.250.160.189</host>
<port>9000</port>
</replica>
<replica>
<host>10.250.160.190</host>
<port>9000</port>
</replica>
</shard>
</test_cluster>
</clickhouse_remote_servers>
</yandex>
注意internal_replication这个参数默认是false,由ClickHouse分别写入多个副本中,但没有检查是否写入成功,这样会导致副本之间数据不一致的问题。
解决方案:将此参数设置为true并借助ZooKeeper + ReplicatedMergeTree方式。
使用clickhouse-client连接上去,查看集群:
总结ClickHouse为啥这么快
- 在计算机系统里,有一个概念叫SIMD,即单指令流多数据流(Single Instruction Multiple Data),是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。这种方式,极大的提升了数据的查询效率,因此可以做到即使是全表扫描,也能达到很高的性能;
- 通过高效的压缩减少IO,读写都是成批读写的;