DNS原理
上一篇文章说到HTTP的一些基本知识点,当我们在浏览器输入网址的时候,浏览器会生成HTTP请求报文,然后委托操作系统的协议栈将数据打包发送出去,其实在发送数据之前还有一步,就是通过域名找到IP,这样才能找到目标网站服务器。操作系统提供的Socket库包含一个域名找IP的方法。
DNS:Domain Name System(域名解析系统)。是用来把域名解析成IP的一套系统,为什么需要DNS呢?我们的网址不能直接用IP吗?直接用IP是可以,但相对来说,域名更容易让我们记住,而且IP可能会变动,如果迁移到新的机器,只需要把原来的域名绑定到新的IP上面就行了。
既然说到IP,就顺便看一下IP的基本知识。
IP
IP由4个部分组成,每一部分占8比特。
设计一套DNS
那么,知道这些以后,如果让你设计一套域名解析系统,你会怎么设计?需要考虑到哪些因素呢?
建立域名对应IP的一对一映射,DNS把映射关系保存到本机,客户端发送域名过来,DNS找到域名对应的IP返回,完事。很简单的一个思路,有什么问题吗?
- 如果只有一台DNS,全世界的域名解析都请求到这一个DNS服务器,服务器肯定受不了,必须采用多台DNS,而且全世界有那么多域名,那单台服务器需要保存的数据量太大了,查询效率上面肯定很低下
- 如果是多台DNS,映射关系分散存储,怎么知道某个域名存在哪台DNS?顺序查找?效率太低。能不能用索引的思路解决?
- 域名解析是高频率的一个动作,要考虑使用缓存
- 映射关系要不要做冗余存储来防止单点故障,冗余存储的话,涉及到更新操作(比如某个域名绑定到新的IP)如何同步?
- 传输层使用TCP还是UDP?
针对上面考虑到的因素,我们的实现方案:
- 多台DNS
-
根据域名层级来做索引
按域名的层级来分段索引到对应的DNS服务器的IP。比如要找到www.google.com对应的IP,首先询问DNS根服务器找到www对应的DNS1,去DNS1找到www.google对应的DNS2,再去DNS2找到www.google.com对应的IP。等等,www开头的多了去了,考虑到索引的效率,应该把高区分度的放在前面。
- 传输层使用UDP就好了,因为数据量很小不需要分成多个包
依照上面的思路,DNS架构是这样的:
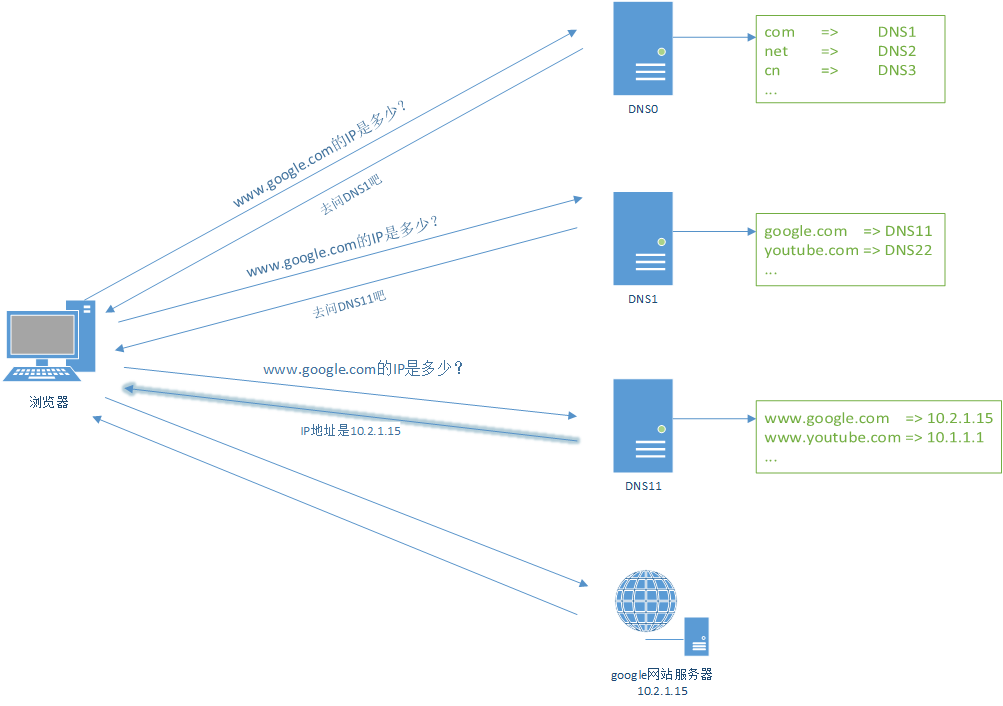
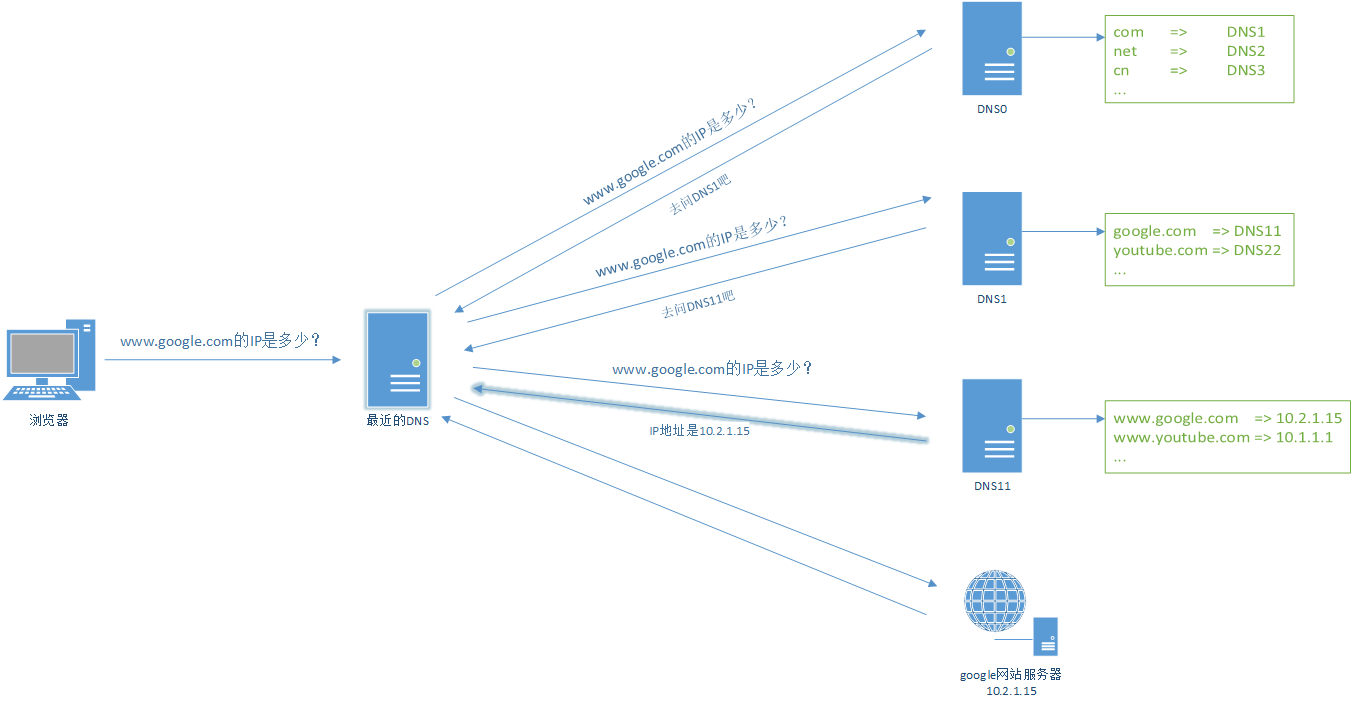
按照上面的流程,浏览器需要自己实现多次寻址请求,如果加一台代理去实现会好一点,这样来说对于应用程序来说就是透明的,应用程序只需要调用一次寻址请求就可以了,改进后的架构图是这样的:
未完待续。。。